Logistic Regression
*note* if you just want to play with the source code check out my GitHub for the final, revised, easy to run code or go to the bottom of the page. For you hardcore mathy folks… just read through
Logistic Regression or Logit Regression is a regression model where the dependent variable is categorical. The model is composed of some set of variable weights, w, and takes in data, x, to make predictions about y, the dependant variable.
Binary Classification
The simplest case of logistic regression is binary classification. That is, where the output can take on one of two values. For some variable y it must belong to a set A which is typically written as:
![]()
A could similarly be written to take on values like (‘Pass’,’Fail’), (True,False), (‘Heads’,’Tails’) et cetra.
Logistic Regression tries to estimate y by finding the answer to:
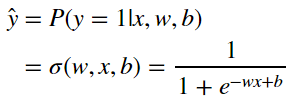
The Sigmoid Function
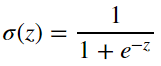
The first question you might have is: Why do we want to use the sigmoid function? The following python code will plot the sigmoid function for some input z
# Import some useful libraries
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
# Computes the sigmoid on an array of values elementwise
def sigmoid(z):
return 1/(1+np.exp(-z))
# Sample the sigmoid function in z
z = np.arange(-10,10,.05)
a = sigmoid(z)
############################## Plot ###############################
# Set some fun Plot Parameters
params = {'legend.fontsize': 'xx-large',
'figure.figsize': (10, 5),
'axes.labelsize': 'xx-large',
'axes.titlesize':'xx-large',
'xtick.labelsize':'xx-large',
'ytick.labelsize':'xx-large'}
pylab.rcParams.update(params)
# Setup Subplot
fig = plt.figure()
plt.title(r'$\sigma(z)$ vs. $z$')
plt.ylabel(r'$\sigma(z)$')
plt.xlabel('z')
plt.plot(z,a)
plt.show()
###################################################################
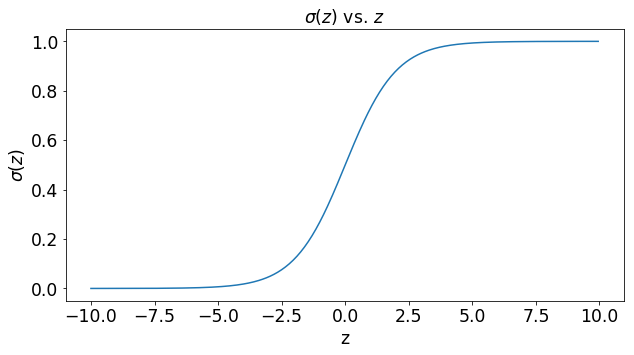
Upon closer look, we can see that the sigmoid function takes on values continuously between 0 and 1 which is ideal for the creation of the probability function we require for binary classification.
Logistic Regression Computational Graph
A compuational graph of logistic regression can be made that makes it easy to see the steps required to generate estimates. That graph can be seen below
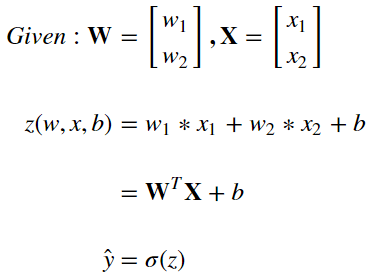
This should make it fairly clear how to compute estimates of y via y hat
Computing the Cost Function
Now that our model can generate estimates, how can we calculate the required updates of our model parameters (w,b) in order to correct the error between our model and the true value?
The function that calculates this error on a sample by sample basis is called the loss function. It generally takes the form of:
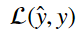
This equation takes the estimate of y and y and returns a metric of the difference between the two.
With logistic regression that loss function typically takes on the form
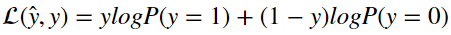
Talking through it, it states that if the label y is equal to 1, then the loss is equal to log(P(y=1)|x,w,b). If the label is zero then the loss is equal to log(P(y=0|x,w,b))
The Cost function is computed over many examples of x and y. Therefore the cost function is an average of the output of the loss function computed as
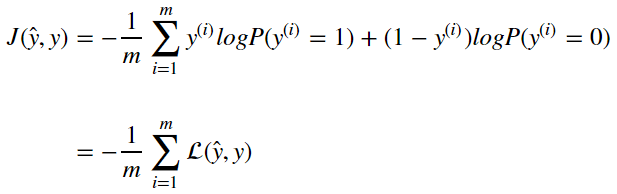
Updating Parameters From Cost
How do we actually update the parameters of linear regression as a function of the loss? Prefereably we’d take a look at the loss function and try to move the parameters so that the loss function is minimized. This can be achived by finding the gradient of the loss function with respect to the parameters and applying it to the original parameter. We must find:
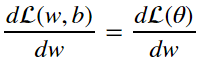
from the equations in section 4 we can deduce through the chain rule that:
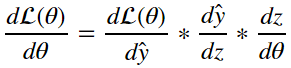
as a result we can surmise that:
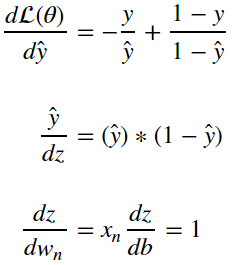
and therefore:
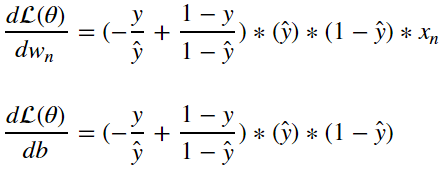
Once we’ve computed these gradients, we can update each parameter by nudging the parameters by some step size in the direction of the gradient. This will have the result of reducing the cost the new model would generate if it observed the same input samples. This is just one way in which we can update the logistic regression model, in order to learn more about this process check out the post on optimization algorithms.
Of course, we typically wont update the model off of the basis of a single input sample. We’d want compute the gradient of the cost function. Following from above this simply becomes:
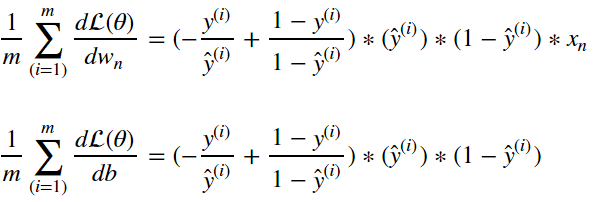
Now we have all the elements required to update our logistic regression model with stochastic gradient descent. The process follows the following flow:
Logistic Regression with Stochastic Gradient Descent:
- Wrangle data
- Initialize model
- Compute model estimates from samples
- Compute updates
- Apply updates
- Repeat steps 3, 4, and 5
this process is reflected in the code below:
# Wrangle Data
n = 1000 # number of steps
m = 1000 # Samples per step
k = 2 # number of features
dims = {'numExperiments':0,'numSamps':1}
class1 = np.random.uniform(-10,10,(k,m))
class2 = np.random.uniform(-5,5,(k,m))
x = np.concatenate((class1,class2),axis=1)
y = np.concatenate((np.ones((1,m)), np.zeros((1,m))),axis = 1)
plt.show()
fig = plt.figure()
plt.title('x vs. y')
plt.ylabel('y')
plt.xlabel('x')
plt.scatter(class1[1],class1[0],label='Class 1')
plt.scatter(class2[1],class2[0],label='Class 2')
plt.legend()
eps = 1/(10**7) # for numerical stability
# Initialize Model
weights = np.random.randn(k,1) # Initialize the weights to a random value
bias = 0 # Initialize bias parameter to 0
learningRate = .01
biasLog = []
weightLog1 = []
weightLog2 = []
costLog = []
for i in range(n):
weightLog1.append(weights[0])
weightLog2.append(weights[1])
# Compute the model estimates recall z = w'x+b a = sigma(z)
z = np.dot(weights.transpose(),x)+bias
a = sigmoid(z)
# Compute the Updates
J = (y*np.log(a)+(1.0-y)*np.log(1-a))
costLog.append(np.mean(J,axis=1))
dyhat = (-y/(a+(eps)))+(1.-y)/((1.-a)+(eps))
dz = a*(1.-a)
dwn = x
dw = np.mean(dyhat*dz*x,axis=1,keepdims=True)
db = np.mean(dyhat*dz,axis=1,keepdims=True)
# Apply Updates
weights = weights - learningRate*dw
bias = bias-learningRate*db
def prediction(weights,bias,x):
z = np.dot(weights.transpose(),x)+bias
a = sigmoid(z)>.5
return(a)
We can see that these two classes slightly overlap and the stochastic gradient decent algorithm finds the decision line that minimizes the errors.
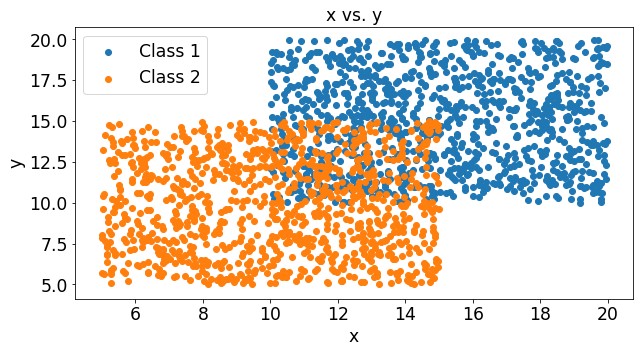
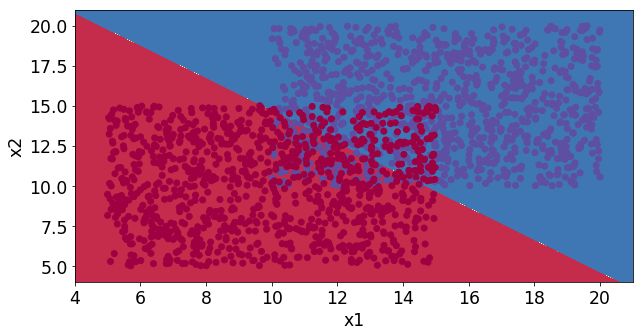
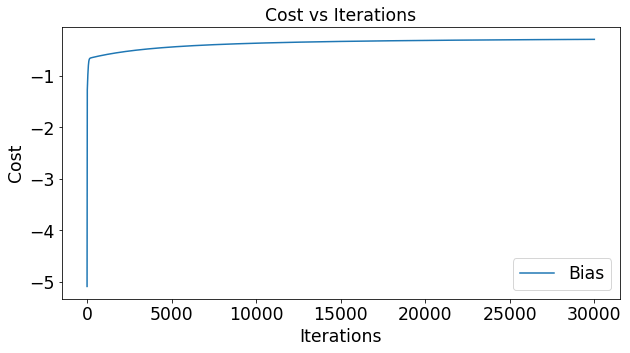
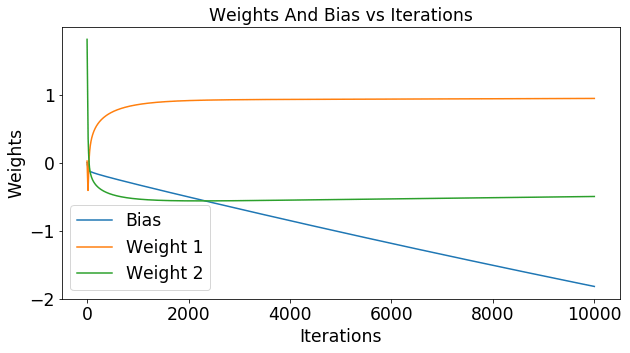
Impact of Samples per Update
Lets say that the function you use to estimate y is completely random. What would that mean for the cost function? Below we’ve plotted the cost for 1000 experiments that had 2 samples in each experiment. In the figure below you can see the cost of each of these experiments. You can see that a random guesser produces an average cost of around .74 and a fairly large variance of .04.
# Set up variables
import numpy as np
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import matplotlib.animation as manimation
# Import movie writer
FFMpegWriter = manimation.writers['ffmpeg']
metadata = dict(title='Movie Test', artist='Matplotlib',
comment='Movie support!')
writer = FFMpegWriter(fps=2, metadata=metadata)
# Compute Loss
def computeLoss(y,yhat):
return y*np.log(yhat)+(1-y)*np.log(1-yhat)
# Compute sigmoid
def sigmoid(z):
return 1/(1+np.exp(-z))
# Setup figure
fig = plt.figure()
plt.ylabel(r'Cost')
plt.xlabel('Experiment')
l, = plt.plot([], [],'o')
plt.xlim(0, 1000)
plt.ylim(.25,1.25)
with writer.saving(fig, "writer_test.mp4", 100):
n = 1000 # number of experiments
dims = {'numExperiments':0,'numSamps':1}
var = []
mu = []
for m in range(1,100,4):
y = np.random.uniform(0,1,(n,m))>.5
yhat = sigmoid(np.random.uniform(0,1,(n,m)))
loss = computeLoss(y,yhat)
cost = -(np.mean(loss,axis=dims['numSamps']))
mu = np.mean(cost)
var = np.var(cost)
plt.title(r'Experiment (%d samples) vs. Cost $\mu$ = %.3f $\sigma$(cost)=%.3f)' % (m,mu,var))
l.set_data(range(n), cost)
writer.grab_frame()
plt.close(fig)
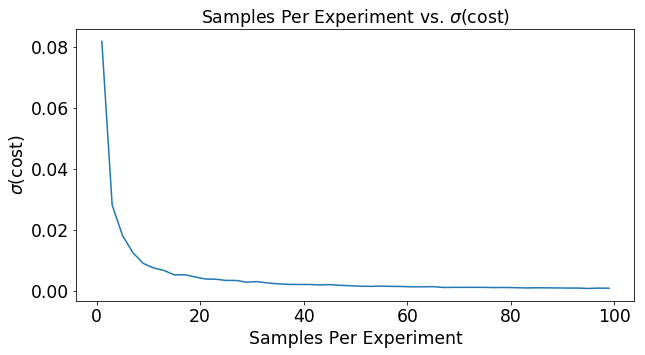
The graph below shows the effect of increasing the number of samples per experiment on the variance of the cost function. As the number of samples goes up, the variance in the ultimate cost estimate drops. This means that you will more reliably move down the cost function in the right direction as you base your decision on more data.
n = 1000 # number of experiments
mSet = range(1,100,2) # samples per experiment
dims = {'numExperiments':0,'numSamps':1}
var = []
mu = []
for m in mSet:
yhat = sigmoid(np.random.uniform(0,1,(n,m)))
y = np.random.uniform(0,1,(n,m))>.5
loss = computeLoss(y,yhat)
cost = -(np.mean(loss,axis=dims['numSamps']))
mu.append(np.mean(cost))
var.append(np.var(cost))
def computeLoss(y,yhat):
return y*np.log(yhat)+(1-y)*np.log(1-yhat)
# Compute the cost function of each sample
fig = plt.figure()
plt.title(r'Samples Per Experiment vs. $\sigma$(cost)')
plt.ylabel(r'Samples Per Experiment')
plt.xlabel('$\sigma$(cost)')
plt.plot(mSet,var)
plt.show()
fig = plt.figure()
plt.title(r'Samples Per Experiment vs. $\sigma$(cost)')
plt.ylabel(r'Samples Per Experiment')
plt.xlabel('$\mu$(cost)')
plt.plot(mSet,mu)
plt.show()
And that is all I have to say about logistic regression with stochastic gradient decent! There are many different methods to optimize stochastic gradient decent. Maybe we’ll take a look at that in a later post.
If you’re interested in playing around with the source, you can grab the jupyter notebook I used to generate this post on my git hub at GitHub: 3dbabove
# Import Packages
import numpy as np
# Create Data Set
def createDataSetOverlapSquares(k,m):
"""
Create the data set used in regression
Arguments:
- k - The number of input features
- m - The number of samples to generate
Return:
- x - The (k,m) Data
- y - The (1,m) labels
"""
assert(k>0 and m>0)
dims = {'numExperiments':0,'numSamps':1}
class1 = np.random.uniform(10,20,(k,m))
class2 = np.random.uniform(5,15,(k,m))
xTrain = np.concatenate((class1,class2),axis=1)
yTrain = np.concatenate((np.ones((1,m)), np.zeros((1,m))),axis = 1)
class1 = np.random.uniform(10,20,(k,m))
class2 = np.random.uniform(5,15,(k,m))
xTest = np.concatenate((class1,class2),axis=1)
yTest = np.concatenate((np.ones((1,m)), np.zeros((1,m))),axis = 1)
return xTrain,xTest,yTrain,yTest
# Initialize The Model
def initializeModel(k):
"""
Initializez the weights and bias used in the model
Arguments:
- k - The number of input features
- m - The number of samples to generate
Return:
- x - The (k,m) Data
- y - The (1,m) labels
"""
assert(k>0)
weights = np.random.randn(k,1) # Initialize the weights to a random value
bias = 0 # Initialize bias parameter to 0
return weights,bias
# Define the sigmoid function
def sigmoid(z):
"""
For arbitrary input size, takes the element wise sigmoid
Arguments:
- z - the input to the activation function
Return:
- a - value of sigmoid(z) for each element of z
"""
a = 1/(1+np.exp(-z))
return a
# compute costs
def computeCostsAndGradients(weights,bias,x,y):
"""
compute the cost and gradient of the forward pass using x and y
for a model containing weights and bias
Arguments:
- weights - the weights of the model
- bias - the model bias
Return:
- x - the x input to the model
- y - the expected label
"""
# For numerical Stability
eps = (1/10**7)
# Compute the model estimates recall z = w'x+b a = sigma(z)
z = np.dot(weights.transpose(),x)+bias
a = sigmoid(z)
# Compute the Updates Chain Rule Intermediates
cost = -np.mean(y*np.log(a)+(1.0-y)*np.log(1-a))
dyhat = (-y/(a+(eps)))+(1.-y)/((1.-a)+(eps))
dz = a*(1.-a)
dwn = x
# Compute Updates
dw = np.mean(dyhat*dz*x,axis=1,keepdims=True)
db = np.mean(dyhat*dz,axis=1,keepdims=True)
grads = {"dw": dw,
"db": db}
return grads, cost
def optimize(weights,bias,xTrain,yTrain,iterations,learningRate):
"""
Computes iterations number of optimizations
Arguments:
- weights - the weights of the model
- bias - the model bias
- xTrain - the training input
- yTrain - the training label
- iterations - the number of iterations to run
- learningRate - the step size for the optimization
Return:
- parameters - the weights and bias of the learned model
- grads - the gradients at each step
- costs - the cost at each step
"""
costs = []
for i in range(iterations):
grads,cost = computeCostsAndGradients(weights,bias,xTrain,yTrain)
dw = grads["dw"]
db = grads["db"]
#simple stochastic gradient descent
weights = weights-learningRate*dw
bias = bias-learningRate*db
costs.append(cost)
parameters = {"weights":weights,
"bias":bias}
grads = {"dw":dw,
"db":db}
return parameters,grads,costs
def prediction(weights,bias,x):
"""
Performs a prediction of y for input x and model defined by weights and bias
Arguments:
- weights - the weights of the model
- bias - the model bias
- x - the inputs we'd like to predict for
Return:
- a - the prediction from inputx
"""
z = np.dot(weights.transpose(),x)+bias
a = sigmoid(z)>.5
return(a)
def model(xTrain, xTest, yTrain,yTest, iterations = 10000, learningRate = 0.01):
# Initialize the weights and bias
weights, bias = initializeModel(xTrain.shape[0])
parameters,grads,costs = optimize(weights,bias,xTrain,yTrain,iterations,learningRate)
weights = parameters["weights"]
bias = parameters["bias"]
yPredTest = prediction(weights, bias, xTest)
yPredTrain = prediction(weights, bias, xTrain)
predTestRes = yPredTest == yTest
predTrainRes = yPredTrain == yTrain
print(predTestRes.shape)
d = {"weights":weights,
"bias":bias,
"predTestRes": predTestRes,
"predTrainRes":predTrainRes}
return d
# Create the data set
k = 5 # Two variables
m = 1000 # 4000 samples per iteration
xTrain,xTest,yTrain,yTest = createDataSetOverlapSquares(k,m)
# Call the model for generation and optimization
modelVar = model(xTrain, xTest, yTrain,yTest, iterations = 5000, learningRate = 0.01)

One thought